Sparse Tensors are n-dimensional vectors with the property of having a significant portion of its elements being zero. Sparse matrix algorithms play a crucial role in modern artificial intelligence and deep learning systems, which is built on the top of linear algebra algorithms. In many scenarios, less than 0.01% of a sparse tensor’s entries may be non-zero. As a result, it is more memory efficient to record ONLY the locations and values of the non-zero entries. One real-life example lies in neural network pruning, where a large portion of model weights can be zeroed out without accuracy loss. To fully realize the benefits of neural network pruning, efficient sparse matrix algorithms are essential.
There are various methods of representing Sparse Tensors: Compressed Sparse Row (CSR), Compressed Sparse Column (CSC), Coordinate Format (COO), ELLPACK Format (ELL), etc. To perform linear algebra operations efficiently, using the appropriate format is crucial. For instance, in sparse matrix multiplication , if matrix is in CSR format while matrix is in CSC format, the computation is significantly more efficient than when both matrices are in CSR format. This necessitates flexible conversion between sparse tensor formats during computation, making efficient conversion algorithms essential.
However, due to the diversity of sparse matrix formats, the workload of creating conversion algorithms for each pair of sparse matrix formats is enormous. For example, with 20 different formats, we would need 400 conversion algorithms. For sparse tensor compilers like MLIR sparse tensor dialect (which they call sparsifier) that allow custom sparse matrix formats (referred to as encodings), it becomes even more impractical to write conversion algorithms for all possible format pairs. Mathematical libraries like Intel MKL typically address this by selecting an intermediate format and implementing conversions between each format and this intermediate format (and vice versa), enabling conversion between any pair of formats through the intermediate format. [2] Even for general-purpose sparse tensor compilers like MLIR sparse tensor dialect, they employ ”operator staging” to split the conversion operation into two steps, using COO format as an intermediate representation. This conversion strategy is not complexity-optimal for many format pairs, and the intermediate format design introduces unnecessary storage overhead.
To address the sparse tensor format conversion problem, we implemented the conversion approach described in the paper ”Automatic Generation of Efficient Sparse Tensor Format Conversion Routines.” [2] This conversion methodology is fundamentally divided into three stages. First is coordinate remapping, which defines functions on the coordinates of a source format’s non-zero values. The output are coordinates that assist in knowing where to insert the non-zero values in the target format. The second crucial component are Attribute Queries, which are SQL-like queries that compute information on the source tensor in order to know how much memory to allocate for the target tensor. Abstract Assembly utilizes the results from coordinate remapping and attribute queries to do the final insertion of non-zero values, completing the conversion.
While our team initially explored both the MLIR sparse tensor dialect and TACO compiler approaches, we ultimately focused our implementation on extending the TACO compiler framework. The MLIR sparse tensor dialect, while promising with its universal encoding to define sparse tensor format and operations like foreachOp and convertOp, presented significant implementation challenges. Our successful implementation using TACO demonstrates the effectiveness of direct conversion pathways without relying on intermediate formats like COO, achieving competitive performance against established libraries for various conversion scenarios.
In our implementation, we referenced three essential papers, listed in order by
precedence.
The Tensor Algebra Compiler (TACO), by Kjolstad et al. [3]
This paper describes the implementation of the compiler that generates efficient code
for tensor expression evaluation. This paper introduces the basic concept of
generating efficient code for evaluating a combinatorial many number of different
tensor expressions.
Format Abstraction for Sparse Tensor Algebra Compilers, by Chou et al. [1]
This paper extends TACO, which had only previously supported a small subset of
tensor formats. This paper introduces level formats, which describe a dimension of a
tensor, providing an interface on how to do certain operations on the level. The paper
introduces six different level formats, which can be composed to form many popular
sparse tensor formats.
Automatic Generation of Efficient Sparse Tensor Format Conversion Routines, by
Chou et al. [2]
This paper
introduces coordinate remapping, attribute query, and abstract assembly.
To fulfill each of these new interfaces, the work of the prior two papers are used to
generate code for iterating through a source tensor’s non-zero values and
to generate code for inserting those non-zero values into a target tensor’s
output.
The Tensor Algebra Compiler base implementation is provided open-source on
GitHub. However, to the extent of our knowledge, Format Abstractions and
Sparse Tensor Conversions were implemented as TACO extensions and the
source is not publicly accessible. In summary, we have five contributions.
1. Implementation of Format Abstractions.
2.
Implementation of Coordinate Remapping Notation
3. Implementation of Attribute Query
Language
4. Implementation of Tensor Abstract Assembly
5. Benchmarking
of our implementation of Sparse Tensor Conversions
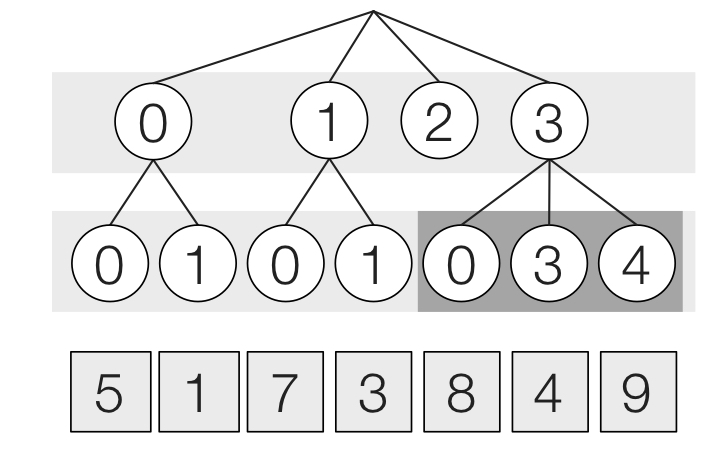
Sparse tensors can be represented as coordinate hierarchies of level formats. In order to access a tensor’s non-zero elements or iterate through a tensor’s elements, a user starts at the top of the hierachy and moves down. This is best illustrated by the CSR example shown in Figure 1. We describe CSR’s first dimension (rows) as dense, as we have an entry for each row despite row ”2” being empty. We describe CSR’s second dimension (columns) as compressed, as for each row, we do not record zero entries.
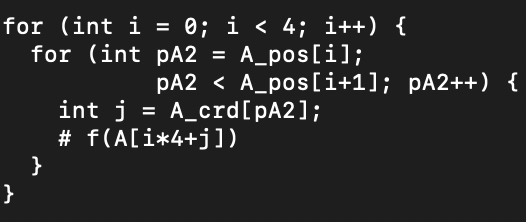
We implemented each level format with two important interface methods: an iteration method, and an insertion method. There are a few extra helper function methods. When generating efficient code for traversing the non-zero elements, we go from the top level-format to the bottom level-format. We continue our previous CSR example by seeing the generated code in Figure 2. We can see that the outer loop corresponds to the dense layer, which simply iterates through each row (i). We also see the inner layer corresponds to the compressed layer, which iterates through the non-zero elements by using the pos array to keep track of which indices go to which parents (which i) and a crd array to specify the coordinate of the next dimension (which j).
The most important concept is that traversal at a single layer of the level format is agnostic to the other level formats in the composition. Therefore, once a level format is implemented, it can be easily integrated to generate code with other level formats. Another important concept is that level formats can be slightly configured to reflect various properties, such as whether the elements are ordered, are unique, or may contain zero values (e.g. ELL can contain zero values when one row has more non-zeroes than another).
These level formats were implemented via C++ inheritance. The base implementation included implementations for Dense, Sparse, and Singleton. We extended these three methods with the iteration and insertion level functions and also introduced three new formats: squeezed, offset, and sliced.
Coordinate Remapping Notation is a specification from the user that describes how the coordinates of a source tensor translates to the coordinates of a destination tensor. These coordinates can give important information on how nonzeros are grouped together in memory. Let’s take a look at the coordinate remapping of a dense tensor to an ELL sparse tensor in Figure 3.
There are two important features to focus on. First is how despite ELL being a 2-dimensional tensor, it has three coordinates in the schema. We used the additional dimension as a way to specify nonzero entries that would be in the same row of the ELL output. We will never be physically materializing a third dimension, but we logically use a third dimension to group together nonzeros in ELL. Second, is the #, or the counter symbol. Upon inserting (i2,i3) into ELL, we consider how many values have already been inserted for that given row. The first element of each row will have the same #i2 value (=1) and thus be grouped together. These computed coordinates to have a better sense of how and where to insert into the target tensor format.
Although the concept of coordinate remapping is simple enough, the implementation was non-trivial. Initially, the TACO source code provided us an implementation of Einsum notation, which includes a lexer, parser, and IR that can form the basic remapping notation. However, the base code had not previously performed any operations on index variables. As a result, we had to implement the logic and grammar for adding, subtracting, and other various operations on index variables. The list of operations supported are shown in Figure 4, sourced straight from the paper. This required extending the parser to handle and translate index expressions into IR, as opposed to just accepting pure index vars.
Attribute Queries are queries associated with a target tensor, targeted towards gathering information for allocating the correct size of the result tensor. For instance, CSR requires an attribute query that fetches how many non-zero elements are in each row. The result of this query is used to figure how where to insert a non-zero into the result tensor. These attribute queries are agnostic of the format of the source tensor: the user provides the list of attribute queries necessary to be computed, and our algorithm generates code.
We implement attribute queries as suggested by the paper: lowering the attribute queries as matrix expressions. The authors of the paper found that many attribute queries can be rephrased as matrix expressions, which they have sought to evaluate. Thus, our role in implementing attribute queries is two-fold: first, discovering the provided API for generating the code for evaluating matrix expressions, and second, translating attribute queries into matrix expressions. Once complete, we pass the results of the queries into the final phase, which orchestrates the conversion process.
The final phase, abstract assembly, puts together all the pieces. There are often three phases. The first phase computes the results of attribute queries, potentially using coordinate remapping. The second phase utilizes the results of the attribute queries, allocating the memory and data structures of the result tensor. The third phase is another iteration over the result of the attribute queries, using coordinate remapping and attribute queries to insert non-zeroes into the resulting tensor.
To show this in action, we show an excerpt of a generated conversion from CSR (B) to ELL (A). Lines 1-5 correspond to phase one, where we compute an attribute query that gets the maximum number of elements in any given row of the input source tensor. Lines 6-11 correspond to phase two, where since we know the maximum number of elements in any row, we know exactly how many rows to allocate for the ELL result tensor. Lines 12-22 correspond to phase three, where we use coordinate mapping to insert the current non-zero element into the right position. Lines 24-27 are just wrapping up the evaluation.
12int32_t A1_attr_max_coord = 0; 3for (int32_t i = 0; i < B1_dimension; i++) { 4 A1_attr_max_coord = TACO_MAX(A1_attr_max_coord, 5 (int32_t)(B2_pos[(i + 1)] - B2_pos[i])); 6} 7A1_ub = (int32_t*)malloc(sizeof(int32_t) * 1); 8A1_ub[0] = A1_attr_max_coord; 9A3_crd = (int32_t*)calloc(A1_ub[0] * A2_dimension, 10 sizeof(int32_t)); 11int32_t A_capacity = A1_ub[0] * A2_dimension; 12A_vals = (double*)calloc(A_capacity, sizeof(double)); 13for (int32_t i = 0; i < B1_dimension; i++) { 14 int32_t count150 = 0; 15 for (int32_t pB2 = B2_pos[i]; pB2 < B2_pos[(i + 1)]; pB2++) 16 { 17 int32_t j = B2_crd[pB2]; 18 int32_t pA2 = count150 * A2_dimension + i; 19 A3_crd[pA2] = j; 20 A_vals[pA2] = B_vals[pB2]; 21 count150++; 22 } 23} 24 25A->indices[0][0] = (uint8_t*)(A1_ub); 26A->indices[2][1] = (uint8_t*)(A3_crd); 27A->vals = (uint8_t*)A_vals; 28return 0; 29
We used an AWS EC2 Instance (m4.16xlarge) to test our code. We conducted our experiemnts on a 2.4 GHz Intel Xeon E5-2686 v4 machine with 256 GiB of Main Memory. The L3 Cache is 2 instances of 90 MB. The machine runs Ubuntu 24.04. We compiled our auto-generated code using GCC 13.2.0. We ran each experiment 10 times with cold cache conditions and report average serial execution times. We compared the performance with the performance of SPARSKIT (SKIT) and Intel Math Kernel Library(MKL).
We utilized four different sparse tensors and four different conversions. When picking these four tensors, we focused on choosing a diverse set of dimension sizes and number of nonzero elements. The details can be see in Table 1. In addition, we picked two symmetric matrices (pdb1HYS, pwtk), and two asymmetric matrices (majorbasis, webbase-1M). For the four different conversion formats, we picked two that SKIT and MKL have hand-optimized implementations for (COO to CSR, CSR to CSC) and two that they do not support (CSC to DIA, CSC to ELL). These matrices are sourced from the SuiteSparse Matrix Collection.
Our results can be seen in Figure 5 and Figure 6. We first take a look at the two direct conversion cases. For the direct conversions supported by SKIT and MKL, the hand implementations often outperform our generated code. SKIT’s hand-optimized code is consistently faster than our TACO implementation, ranging from an extreme 1.9x speedup in COO to CSR in webbase-1M to just a more reasonable 1.14x speedup in CSR to CSC for pwtk. There are occurences, however, where our auto-generated code beats MKL’s code, such as both COO to CSR and CSR to CSC for majorbasis.
This is unfortunate, as the prototype raised in the paper was able to remain competitive with SKIT across all of the matrices they tested on. In addition, the authors’ implementation would most often outperform the MKL implementation.
However, for conversions that require an intermediary, CSC to DIA and CSC to ELL, our auto-generated code beats out the hand-optimized versions by a large margin. For instance, in CSC to DIA in majorbasis, Our TACO implementation has a 1.8x speedup over SKIT and a whopping 2.35x speedup over MKL. For CSC to ELL, our implementation beats SKIT for every input tensor, with a peak of a 2.18x speedup in pwtk. This showcases the crucial improvement of the original paper: there are a combinatorial many number of different sparse tensor conversions and the auto-generation can help conversion routines scale with an increasing number of different sparse tensor formats.
To explain the disparity between our implementation and the authors’ implementation, the reason likely lies in additional optimizations that take advantage of certain level formats to generate efficient code. For instance, we noticed that in our generated code, our implementation would not utilize CSR’s format to more efficiently answer certain attribute queries. As answering attribute queries are a significant portion of the pipeline, optimizing this case is important if we wanted to reach the level the authors reached.
Our initial approach was to first examine MLIR’s implementation. If MLIR hadn’t implemented the paper’s content, we planned to implement a ”simple” dialect and pass in MLIR (MLIR actually has several ways to lower dialects, with sparse tensor dialect primarily using PatternRewriter). Otherwise, we would implement on TACO like the original paper authors. However, MLIR’s complexity exceeded our expectations.
We initially spent considerable time reading general documentation and tutorials, then carefully examined the sparse tensor dialect’s TableGen code. We discovered that MLIR’s encoding for describing sparse matrix formats was already a superset of what was described in the paper, and the sparse tensor dialect already included operators for efficient traversal and assembly. This led us to believe that implementing attribute queries would be straightforward. We also found that mlir-opt included an s2s-strategy command line option. Following this, we discovered a source code comment link to arXiv pointing directly to the paper we have chosen. So did MLIR implement the conversion methods from the paper? No, or at least we couldn’t find any implementation of attribute queries in the codebase. Attempting to set s2s-strategy to ”direct” only resulted in MLIR throwing errors during pattern rewriting.
This was all due to a mistake we made: using the llvm-project which is a git submodule in Polygeist, which had its most recent commit in October 2023. After switching to the newer version, we found that MLIR’s sparse tensor dialect implementation had changed dramatically. It was in this version we discovered that MLIR converts almost all sparse-to-sparse tensor format conversions by first converting the source tensor to COO, quick sorting it, and then inserting into the destination tensor - a process called operator staging. Disabling staging for convert operators didn’t cause issues for conversions between CSC, CSR, and COO. However, when we conducted performance tests, we found that even with direct conversion, the performance was similar to the indirect version. We suspected this might be because later optimizations eliminated the overhead of copying and sorting, but we didn’t have time for deeper investigation.
An important lesson we learned is not to underestimate the time required to understand existing codebases, especially for compiler projects that rely heavily on complex abstractions (MLIR’s multi-layer architecture makes it even more complex, although one benefit of layered design is that we can ignore many low-level implementations). As students not fully immersed in industrial-scale projects, we’re accustomed to having complete knowledge of our codebases in a few days. However, this is often because assignment and project codebases don’t need to solve real-world problems and inherently lack complexity. We pay tribute to MLIR’s developers, especially Peiming Liu, the main contributor to sparse tensor dialect and the convert operator in the past year. It’s hard to imagine how they made so many contributions to such a complex project in a year without compensation, to the extent that the two versions we examined seemed refactored. We believe we will continue to study MLIR’s sparse tensor dialect and try to implement some interesting features to contribute to the community.
Fortunately for us, TACO’s codebase was significantly less complex than MLIR’s, making it possible for us to reproduce the paper’s implementation in TACO.
Our implementation of automatic sparse tensor format conversion has demonstrated the power of automated conversion generation in the sparse tensor compiler. Through our journey from exploring MLIR to implementing the paper’s methodology in TACO, we have gained valuable insights into the challenges and opportunities in sparse tensor compilation.
We successfully implemented the three-phase conversion approach in TACO, encompassing coordinate remapping, attribute queries, and abstract assembly. Our work extended TACO’s format abstraction framework with new level formats and demonstrated competitive performance against established libraries.
However, our implementation faces certain limitations. The performance for direct conversions, such as COO to CSR, still lags behind hand-optimized implementations in some cases. The current attribute query system could benefit from additional optimizations, particularly for formats with special properties. Furthermore, some advanced optimization techniques described in or out the paper remain to be implemented.
Looking toward the future, several promising directions emerge for performance optimization. We can extend our current implementation to support more level formats, optimize attribute query performance, and enable parallel conversion generation. We can also try to expand our research scope. For example, we could integrate our implementation experience into industrial compiler frameworks like MLIR. We can also explore potential frontend applications for sparse tensor compilers.
We agreed that the following work distribution is fair: 60% Roland, 40% Bear.
[1] Chou, S., Kjolstad, F., and Amarasinghe, S. Format abstraction for sparse tensor algebra compilers. Proc. ACM Program. Lang. 2, OOPSLA (Oct. 2018).
[2] Chou, S., Kjolstad, F., and Amarasinghe, S. Automatic generation of efficient sparse tensor format conversion routines. In Proceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation (New York, NY, USA, 2020), PLDI 2020, Association for Computing Machinery, p. 823–838.
[3] Kjolstad, F., Kamil, S., Chou, S., Lugato, D., and Amarasinghe, S. The tensor algebra compiler. Proc. ACM Program. Lang. 1, OOPSLA (Oct. 2017).
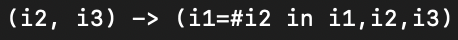

.png)
.png)
.png)
.png)